
カセットI/Fの話(sharp編)
casioの話はこちら
カセットwavのエンコーダ/デコーダ
SC61860系のold系(PC-1245/51/55など)、S1系(PC-1261/65,1350,1401など)、S2系(PC-1360/60K/1470Uなど)の
エンコード、デコードに対応しています。
pcwav-encode.pl version 0.5
pcwav-decode.pl. version 0.5
変更履歴
ver 0.5:S1/S2系の予約語不足分を追加
ver 0.4:S2系の2バイト文字(漢字)対応
ver 0.3:S1/S2 系BASICのwavファイル終端でエラーにならないようにダミーデータFFを入れた
OLD系のSUM計算の誤りを修正した(80バイト=10ブロックでリセットが必要だった)
【使い方】
perl pcwav-encode.pl s1bin input.bin output.wav [filename] [addr]
perl pcwav-encode.pl s1basic input.bas output.wav [filename]
perl pcwav-encode.pl s2basic input.bas output.wav [filename]
perl pcwav-encode.pl oldbin input.bin output.wav [filename] [addr]
perl pcwav-encode.pl oldbasic input.bas output.wav [filename]
perl pcwav-decode.pl raw input.wav output.bin
perl pcwav-decode.pl s1bin input.wav output.bin
perl pcwav-decode.pl s1basic input.wav output.bas
perl pcwav-decode.pl s2basic input.wav output.bas
perl pcwav-decode.pl oldbin input.wav output.bin
perl pcwav-decode.pl oldbasic input.wav output.bas
ソースコードはこちらで公開しています。
ルートにあるbuild.plを実行すると、複数のソースコードが統合されて、上記のファイルが作成されます。
はじめに
先人が開発して配布してくれているいくつかのツールがあります。
有名どころは以下
・こばやしひろゆきさん作の yasm.pl / cload.pl →old系/S1系のマシン語をwavにエンコード/デコードする
・JP3TLCさん作の bas2wav.pl →BASICソースをold系フォーマットのwavにエンコードする
S1系の機種はold系のフォーマットでも読み込めますが、S2系はoldフォーマットを読めないんですよね。
最近PC-1360Kを入手したのですが、解析したりするのにちょっとしたBASICソースを読み込ませたいことがあったりして、S2系wavデータが作れないと地味に不便なんですよね。
ということもあり、今回全てのパターンに対応するツールを開発してみました。
できること
・バイナリ→wav エンコード(old, S1)
・BASIC→wav エンコード(old, S1, S2)
・wav→バイナリ デコード(raw, old, S1)
・wav→BASICテキスト デコード(old, S1, S2)
なんとS1/S2系はカナ文字にも対応しています。
ただし、version 0.1では特殊文字はバイナリ表現しかできません。
たとえばS1/S2系の "√" 記号は "x\FC" という表現にしています。
ところでwav→rawデコードって結構役に立ちますね。開発中はrawデータと睨めっこが続きました(笑)
追記)
最強?ツールのPocket Toolsというのもあって、これはさまざまな系統のエンコード/デコードに対応しています。
が、Windows用なんですよね。
私的には、メインがMacだし、たまにLinuxだったり、まぁWindowsでもいいんだけど、マルチな環境で気軽に動かせるツールが欲しいのです。
まず最初にwavファイルのうんちくを、、、
みなさんよく聞く(笑)ピーヒャララ〜は、基本的に周波数変調の方式で記録されています、というのはPB-100のところでも述べましたが、シャープのは、4,000Hz 8サイクルが1で/2,000Hz 4サイクルが0の500ボーという仕様です。
試しに1行ぐらいのBASICコードを書いて実機でCSAVEしたものをPCで記録すると、以下のような波形を見ることができます。
最初の”ピーーーーー”(リードイン)が8秒ぐらいあって、プログラム本体が”ヒャララ”となります。
このプログラム本体の先頭部分を拡大すると、下の図のようになっています。
4kHzのところと2kHzのところがあることがわかります。

この部分をもう少し詳しくみてみると、、、
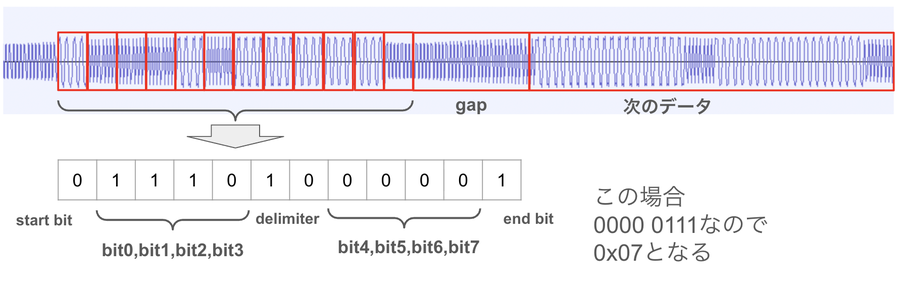
シャープのフォーマットはカシオのに比べて、ちょっと特殊というか、アナログ信号が暴れることを想定して同期を取りやすくするようなフォーマットになっています。
具体的には、
スタートビット0の次に1バイトの半分の4ビットを積んで、その後に区切り記号の1,0を積み、その後に残りの4ビットとストップピット1を積みます(これが約24msec)。で、さらにgapの4kHz信号を6msecおいて、次のデータになります。
この例だと、信号上は1110 0000と積まれていますが、LSBなので実際の論理データは0000 0111となって0x07を表しています。
区切りやgap部分があるので、同期ずれが起こりづらいフォーマット設計になっているんですね。
さて、”ピーヒャラララ”の正体もわかったところで(笑)
ここまでの話はいわゆる物理層の話です。
これをベースに論理的なデータが載るのですが、かなり変態な仕様で理解に苦しみました。
順番に解説していきます。
カセットI/Fフォーマット
以下はS1系ベースの説明で、old系は少し異なります。
全体として、ヘッダ+本体で構成される
ヘッダは、リードイン4kHz8秒+データ種別(後述)+ファイル名(8バイト)+チェックサム、さらにパスワードありの場合はパスワード(8バイト)+チェックサムとなっています。
ファイル名はなぜか8バイト目にF5が必要なので実質7バイトまでしか入らないです。7バイトに満たない場合は0で埋められて、逆順に配置される。たとえば"ABC"ならば"00 00 00 00 43 42 41 F5"となる。
パスワードのフォーマットもファイル名と同様です。
本体は120バイトごとにチェックサムが入り、残り部分の最後にはエンドマークFFが二つ入りその後にチェックサムが付く。
本体データはニブルスワップ(1バイトデータの中の4bitを上位下位で入れ替える)されたものが出力されるのでややこしい。
さらにチェックサムの計算方法がかなり特殊。
本体120バイト毎のチェックサム計算
本体データをニブルスワップしてからチェックサム計算し、そのチェックサムもニブルスワップして出力。
またこの結果は次のチェックサムに累積される。(←これが最初わからなくてハマった)
最後の残りデータはエンドマークのFFをひとつ追加した状態で計算するが、
元のロジカルデータ(ニブルスワップしない)の上位ニブル→下位ニブルの順で加算する。上位ニブルの時だけキャリー補正を入れる。そして計算されたチェックサムをニブルスワップして出力する。(←これも最初全くわからなくて現物合わせした)
もう、ホント意味わからん(笑)




1バイトの構成は先に説明した通り4bitずつに分けられる
start, bit0, bit1, bit2, bit3, 1, 0, bit4, bit5, bit6, bit7, stop + gap
gapは次のバイトとの境界を明確にし、同期ずれを防ぐ役割を持つ。
ちなみに種別は以下
■ old系
|
種別 |
内容 |
|
02 |
BASIC |
|
12 |
BASIC(PASS) |
|
62 |
BINARY |
■ S1系
|
種別 |
内容 |
|
07 |
BASIC |
|
17 |
BASIC(PASS) |
|
67 |
BINARY |
■ S2系
|
種別 |
内容 |
|
27 |
BASIC |
|
37 |
BASIC(PASS) |
S1系フォーマット
S1系は以下のような文字コードと予約語が定義されています。
文字コード(アスキーコードに準拠)
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0x20 | SP | ! | " | # | $ | % | & | ' | ( | ) | * | + | , | - | . | / |
| 0x30 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? |
| 0x40 | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 0x50 | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ^ | _ |
| 0x60 | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 0x70 | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |
予約語
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0x80 | REC | POL | ROT | DEC | HEX | TEN | RCP | SQU | CUR | HSN | HCS | HTN | AHS | AHC | AHT | |
| 0x90 | FAC | LN | LOG | EXP | SQR | SIN | COS | TAN | INT | ABS | SGN | DEG | DMS | ASN | ACS | ATN |
| 0xA0 | RND | AND | OR | NOT | ASC | VAL | LEN | PEEK | CHR$ | STR$ | MID$ | LEFT$ | RIGHT$ | INKEY$ | PI | MEM |
| 0xB0 | RUN | NEW | CONT | PASS | LIST | LLIST | CSAVE | CLOAD | MARGE | OPEN | CLOSE | SAVE | LOAD | CONSOR | ||
| 0xC0 | RANDOM | DEGREE | RADIAN | GRAD | BEEP | WAIT | GOTO | TRON | TROFF | CLEAR | USING | DIM | CALL | POKE | CLS | CURSOR |
| 0xD0 | TO | STEP | THEN | ON | IF | FOR | LET | REM | END | NEXT | STOP | READ | DATA | PAUSE | INPUT | |
| 0xE0 | GOSUB | AREAD | LPRINT | RETURN | RESTORE | CHAIN | GCURSOR | GPRINT | LINE | POINT | PSET | PRESET | BASIC | TEXT | OPEN$ | |
| 0xF0 |
BASICコードの内部表現
たとえば、
10:PRINT ”ABC”
20:END
というコードの場合、
FF プログラム先頭
00 0A 行番号10
07 この行の長さ
DE PRINTの内部コード
22 41 42 43 22 “ABC”のコード
0D 行の終わり(改行コード)
00 14 行番号20
02 この行の長さ
D8 ENDの内部コード
OD 行の終わり(改行コード)
FF プログラムの末尾
となります。
これが本体データとして積まれるわけですが、先頭のFFは含まれず、その次(この例では00)からニブルスワップされて積まれます。
追記)
半角カナのコードはプレフィクス0xFE+SJISコードで表現されています。
例)ア -> FE B1
本ツールでは、PC側で扱いづらいのでエクスポート時にUnicode変換しています。もちろんインポート時には0xFE+SJISに戻します。
S2系フォーマット
S2系の文字コードはS1と同じくアスキーコード準拠です。
しかし、予約語がS1に比べて増えている関係で、7bitで収まらないため、プレフィクス0xFEをつけて表現しています。
以下、予約語
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0x10 | RUN | NEW | CONT | PASS | LIST | LLIST | CLOAD | MERGE | LOAD | RENUM | AUTO | DELETE | FILES | INIT | CONVERT | |
| 0x20 | CSAVE | OPEN | CLOSE | SAVE | CONSOLE | RANDOM | DEGREE | RADIAN | GRAD | BEEP | WAIT | GOTO | TRON | TROFF | CLEAR | USING |
| 0x30 | DIM | CALL | POKE | GPRINT | PSET | PRESET | BASIC | TEXT | WIDTH | ERASE | LFILES | KILL | COPY | NAME | SET | |
| 0x40 | LTEXT | GRAPH | LF | CSIZE | COLOR | DEFDBL | DEFSNG | |||||||||
| 0x50 | CLS | CURSOR | TO | STEP | THEN | ON | IF | FOR | LET | REM | END | NEXT | STOP | READ | DATA | PAUSE |
| 0x60 | INPUT | GOSUB | AREAD | LPRINT | RETURN | RESTORE | CHAIN | GCURSOR | LINE | LLINE | RLINE | GLCURSOR | SORGN | CROTATE | CIRCLE | |
| 0x70 | PAINT | OUTPUT | APPEND | AS | ARUN | AUTOGOTO | ERROR | |||||||||
| 0x80 | MDF | REC | POL | ROT | DECI | HEX | TEN | RCP | SQU | CUR | HSN | HCS | HTN | AHS | AHC | AHT |
| 0x90 | FACT | LN | LOG | EXP | SQR | SIN | COS | TAN | INT | ABS | SGN | DEG | DMS | ASN | ACS | ATN |
| 0xA0 | RND | AND | OR | NOT | PEEK | XOR | POINT | PI | MEM | |||||||
| 0xB0 | EOF | DSKF | LOF | LOC | NCR | NRR | ||||||||||
| 0xC0 | ERN | ERL | ||||||||||||||
| 0xD0 | ASC | VAL | LEN | KLEN | ||||||||||||
| 0xE0 | AKCNV$ | KACNV$ | JIS$ | OPEN$ | INKEY$ | MID$ | LEFT$ | RIGHT$ | KMID$ | KLEFT$ | KRIGHT$ | |||||
| 0xF0 | CHR$ | STR$ | HEX$ |
逆に半角カナ文字はSJISコードそのものです。
BASICコードの内部表現
S1との違いは、予約後にプレフィクス0xFEがつくのと、GOTOなどの飛び先行番号が0x1F+2バイトの行番号という表現になります
ちなみに飛び先行番号の表現はGOTOだけでなく、ON GOTOやGOSUBも同じ。
たとえば、
10:PRINT ”ABC”
20:GOTO 10
30:END
というコードの場合、
FF プログラム先頭
00 0A 行番号10
08 この行の長さ
FE 60 PRINTの内部コード
22 41 42 43 22 “ABC”のコード
0D 行の終わり(改行コード)
00 14 行番号20
06 この行の長さ
FE 2B GOTOの内部コード
1F 00 0A 行番号識別コード0x1F+行番号10
0D 行の終わり(改行コード)
00 1E 行番号20
03 この行の長さ
FE 5A ENDの内部コード
OD 行の終わり(改行コード)
FF プログラムの末尾
S1と同じく、カナ文字コードはエクスポート時にUnicode変換しています。もちろんインポート時にはSJISに戻します。
ver0.4から2バイト文字(漢字)にも対応しています。これもカナ文字と同じくUnicode/SJIS変換しています。
old系フォーマット
old系は文字コードがアスキーコードではなく独自コードです(気持ち悪い)
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0x10 | SP | " | ? | ! | # | % | \ | $ | \PI | \SQR | , | ; | : | @ | & | |
| 0x30 | ( | ) | > | < | = | + | - | * | / | ^ | ||||||
| 0x40 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | . | \EX | \BX | ~ | ||
| 0x50 | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | |
| 0x60 | P | Q | R | S | T | U | V | W | X | Y | Z | |||||
| 0x70 | ASC | VAL | LEN | |||||||||||||
| 0x80 | AND | >= | <= | <> | OR | NOT | SQR | CHR$ | COM$ | INKEY$ | STR$ | LEFT$ | RIGHT$ | MID$ | ||
| 0x90 | TO | STEP | THEN | RANDOM | WAIT | ERROR | KEY | SETCOM | ROM | LPRINT | ||||||
| 0xA0 | SIN | COS | TAN | ASN | ACS | ATN | EXP | LN | LOG | INT | ABS | SGN | DEG | DMS | RND | PEEK |
| 0xB0 | RUN | NEW | MEM | LIST | CONT | DEBUG | CSAVE | CLOAD | MARGE | TRON | TROFF | PASS | LLIST | PI | OUTSTAT | INSTAT |
| 0xC0 | GRAD | INPUT | RADIAN | DEGREE | CLEAR | CALL | DIM | DATA | ON | OFF | POKE | READ | ||||
| 0xD0 | IF | FOR | LET | REM | END | NEXT | STOP | GOTO | GOSUB | CHAIN | PAUSE | BEEP | AREAD | USING | RETURN | RESTORE |
BASICコードの内部表現
たとえば、
10:PRINT”ABC”
20:GOTO 100
100:END
というコードの場合、
E0 10 行番号10(行番号はBCD表現)
C1 PRINTの内部コード
12 51 52 53 12 “ABC”のコード
00 行の終わり
E0 20 行番号20
D7 GOTOの内部コード
41 40 40 ‘1’, ‘0’, ‘0’
00 行の終わり
E1 00 行番号100
D4 ENDの内部コード
00 行の終わり
F0 プログラムの末尾
行番号の表現が特殊なのと行の区切りが0x00、プログラムエンドマークが0xF0
カセットフォーマットの本文のチェックサム仕様
8バイト単位で出力される累積型チェックサムであり、計算は各バイトを上位ニブル・下位ニブルに分解して順次加算する方式で、上位ニブル加算時にはキャリー補正(end-around carry)が行われる。
ただし、この累積値は 80バイトごと(8バイト × 10ブロックごと)にリセット されます。(ハマったww)
算出された値は出力時にニブルスワップされて記録される。
なお最後の余り部分の後はチェックサムが入らない。
(おまけ)
私が使っている環境の話
色々試したけど、これが安定して動作しています。
PC:MacBookAir(M4)
Wav編集ソフト:Audacity
入力側はオーディオインターフェース(M-AUDIOのM-TRACK SOLO)を途中に入れています。
入力レベルが安定する感じ。(たまたま音楽関係の編集をするのでオーディオI/Fを持っているのです)
Pocket Computer --> Cassete I/F --> Audio I/F -(USB)-> Mac
出力側はMac本体のアナログ出力だとレベルが足りないのか、失敗することが多いです。
オーディオI/Fを挟んでもうまくいかないことが多い。
で、GoogleDrive経由でスマホのアナログ出力(ボリュームMAX)を使うといい感じです。
Mac -(Google Drive)-> スマホ --> Cassete I/F --> Pocket Computer
ちなみに、スマホってボリュームMAXで使っていると”耳に悪いよ”的なエラーチェックが走って、適当なタイミングでボリュームが落とされます。機種によるのかもしれませんが。
これ最初気づかず、何度かCLOADしていると、あるタイミングでロードできなくなり、あら???って状態になります。